クラスター分析
クラスター分析とは
クラスター分析とは、異なるものが混ざりあっている集団の中から互いに似たものを集めて集落(クラスター)を作り、対象を分類するという方法の総称です。
「対象」というのは人間とは限らず、企業や商品や地域や、そして時には質問項目を分類する場合もあることに注意してください。このクラスター分析を用いると、標準化された手続に従って対象の分類ができるため、マーケティングリサーチにおいてはポジショニング確認を目的としたブランドの分類や、イメージワードの分類、生活者のセグメンテーションなどに用いられます。
調査データに対してクラスター分析を実行することで、メーカーサイドの視点に立ったブランドの分類や、デモグラフィック要因による生活者の分類とは異なった「生活者サイドの視点に立った分類」を発見できます。
2種類のクラスター分析
クラスター分析には、大きく分けると階層クラスター分析、非階層クラスター分析の2種類の方法があります。
階層クラスター分析
寿司ネタの選好度データから、寿司ネタを分類するために階層クラスター分析を行った結果が下記の図に示されています。
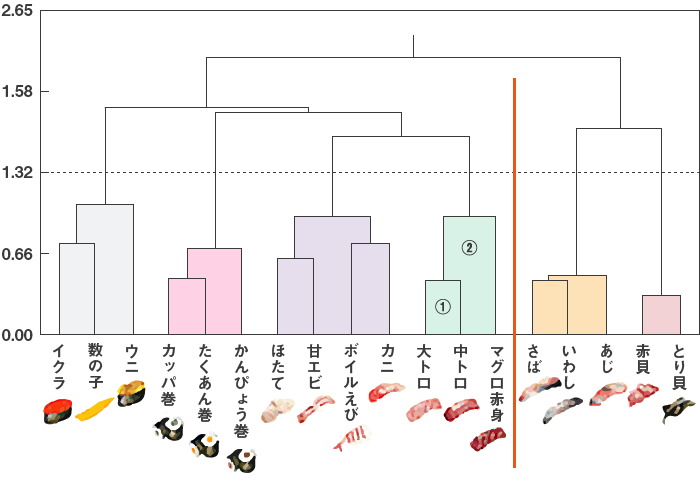
このように、階層クラスター分析を行うとデンドログラム(樹形図)が出力され、各寿司ネタがクラスターとして結合されていく過程を見ていくことができます。
例えば、大トロ、中トロ、マグロ赤身を例にとってみると、大トロと中トロから出ている線がまず結合されます(図中の①)。これは、大トロと中トロがこれ以降一つのクラスターとして結合されたことを表します。さらに②では、これがマグロ赤身と結合されます。これは、大トロと中トロのクラスターにマグロ赤身が組み込まれたことを表します。そしてこの大トロ、中トロ、マグロ赤身からなるクラスターは次に、カニ、ボイルえび、甘えび、ほたてからなるクラスターと結合します。
デンドログラムでは、図の下の方で結合すればするほど近い関係にあるといえるので、大トロと中トロは非常に近く、赤身はそれに次いで近いということがデンドログラムから読み取れるのです。また、最も下で結合している赤貝ととり貝は、これらの寿司ネタの中で最も近い2つとわかり、おおざっぱに言って図中の赤線より左側のクラスターと右側のクラスターは最も遠い関係にあるクラスターであるといえます。
図中の点線部分の高さで判断すると、6つのクラスターが結合されています。ユーザーが判断基準の点線の高さを変えることによって、ユーザーの判断によってクラスターの分割数を決めることができます。
このように階層クラスター分析を行うと、対象を単にいくつかのクラスターに分類するだけでなく、クラスターが結合されていく過程までを直感的なアウトプットで確認することができます。しかしその反面、分類する対象が非常に多い場合には、計算量が非常に多くなってしまい実行不可能になったり、結果の解釈が難しくなったりという欠点もあります。そのため、大規模データの場合は非階層クラスター分析がよく用いられます。
非階層クラスター分析
マーケティングリサーチにおける非階層クラスター分析とは、似たようなパターンのデータを持った対象が、同じグループ(クラスター)に属するように自動でグルーピングを行うアルゴリズムです。
同じクラスターの中に属する対象はなるべく似通っているように、異なるクラスターに属する対象間ではなるべく違いを際立たせる、というのが非階層クラスター分析の目的です。階層クラスター分析とは違い、大量の対象の分類に用いても結果が安定していることが特長で、サンプル数の多いマーケティングリサーチを行った場合の回答者のセグメンテーションに非常によく用いられます。
しかし、非階層クラスター分析では分析者があらかじめ、いくつのクラスターに分類したいかを入力しなければなりません。また得られる結果も、それぞれの回答者がどのクラスターに属するかを示す情報のみであり、階層クラスター分析のようなデンドログラムが得られるわけではありません。そのため、クラスターの内容を知るために、フェイスシートなど他の情報との間でクロス集計をすることがあります。
このような特徴から、非階層クラスター分析を行う際には、「クラスター数をいくつに設定するか」が非常に重要となります。
非階層クラスターの実例
階層クラスターでは寿司ネタの分類を行いましたが、次は寿司ネタの選好データから、好きな(嫌いな)ネタの種類で人を分類してみます。クラスター数の指定を変えながら試行した結果、5つのクラスターに分類することが適当であると判断されました。そこで、非階層クラスター分析によってアンケート回答者を5つのクラスターに分類した結果が下のグラフです。グラフはそれぞれの寿司ネタに対するクラスターごとの選好度の平均を示しています。
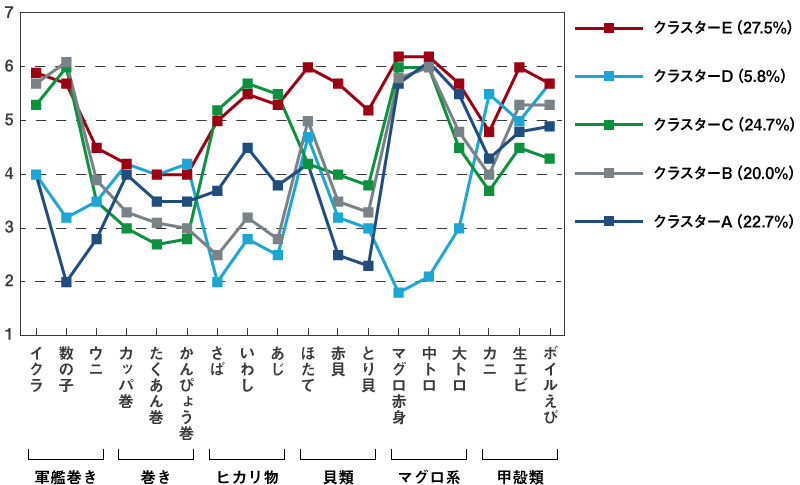
まず青のクラスターAは、数の子・ウニの軍艦巻きと、赤貝・とり貝が嫌いなクラスターであることが分かります。グレーのクラスターBは、巻きとヒカリ物を苦手とするクラスターで、緑のクラスターCは、巻きと甲殻類が苦手で、ヒカリ物が大好きな様子です。水色のクラスターDはマグロ系とヒカリ物が嫌いで、巻きが好きなクラスターであり、ボリュームが全体の5.8%と少ないところが特徴です。赤のクラスターEは、どのネタであろうと大好きなクラスターで、このクラスターの全体に対する構成比は最も大きくなっています。
このように非階層クラスター分析を用いると、似通った傾向を持った回答者をグルーピングすることができます。この例では、寿司ネタの選好度パターンから5つのクラスターに回答者を分類しましたが、他にもブランド選好度によるセグメンテーション、価値観やライフスタイルによるセグメンテーション、購買時の重視点によるセグメンテーションなど様々なセグメンテーションに応用が可能です。
階層クラスター分析と非階層クラスター分析の使い分け
階層クラスター分析と、非階層クラスター分析はこれまで述べてきたように、特長が異なります。以下の表のように使い分けることができます。
※横にスクロールしてご覧ください
| 階層クラスター分析 | 非階層クラスター分析 | |
|---|---|---|
| クラスターに分けたい対象の数(推奨) | 30程度以下 | 100程度以下 |
| よくある分類対象 | 変数(集計結果等) | サンプル |
| クラスター数の決定タイミング | 分析後 | 分析前 |
| 解釈の方法 | デンドログラムを見ながら解釈 | 元データ等とのクロス集計を見ながら解釈 |
| メリット | デンドログラムを見ながら結合の過程を直感的に理解できる | 大量サンプルであってもクラスタの分類が可能 |
| デメリット | 大量サンプルの場合、解釈や計算自体ができなくなる可能性がある | クラスタ数を事前に決定する必要があるため、試行錯誤が必要 初期値依存性がある |
近さの定義
階層クラスター分析にせよ非階層クラスター分析にせよ、分類する対象がそれぞれどれほど「近い」か、もしくは「似ているか」を数量的に定義しなければ実行することはできません。この「近さ」は様々な定義がありますが、その中で最も代表的な「ユークリッド距離」の定義について紹介します。 例として、「”ある商品を購入する際に、重視すること”を基軸に、生活者をセグメンテーションする」というシーンを想定し、それぞれのアンケート回答者間の「近さ」をどのように定義するのかを説明します。
まず、クラスター分析を行うために下記のような質問を利用します。

選ばれた回答に対し、「非常に重要」に7点、「重要」に6点…、「全く重要でない」に1点と点数をつけ、下記のようなデータを作成します。
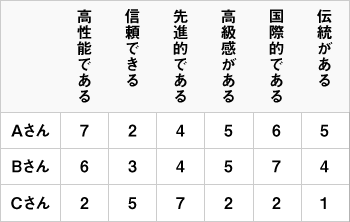
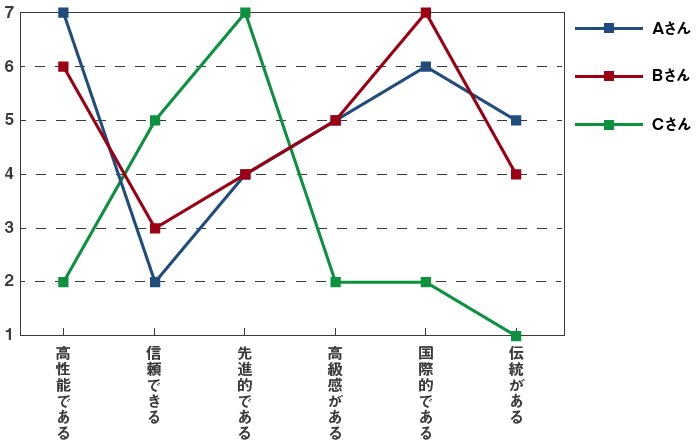
すると下記のようなことが分かります。
- 「高性能である」について、AさんとBさんは 7-6=1 違いがある。
- 「信頼できる」について、AさんとBさんは 2-3=-1 違いがある。
- 「先進的である」について、AさんとBさんは 4-4=0 違いがある。
- 「高級感がある」について、AさんとBさんは 5-5=0 違いがある。
- 「国際的である」について、AさんとBさんは 6-7=-1 違いがある。
- 「伝統がある」について、AさんとBさんは 5-4=1 違いがある。
ここで、プラスの場合もマイナスの場合も同様な差として評価するために、それぞれの項目における差の2乗和の平方根をAさんとBさんの距離として定義し計算すると、以下のようになります。
- AさんとBさんの距離は2.000
- AさんとCさんの距離は9.165
- AさんとBさんの距離は8.485
これをグラフで確認すると、以下のように定義された距離が直感にも支持されます。
このように、「距離」が定義されると「距離」の短い2つのサンプルは「近い」ということになり、クラスター分析はこのように数量的に定義された「近さ」を基に実行されていきます。