潜在クラス分析
潜在クラス分析は、個人の様々な特徴の違いから、統計情報に基づきセグメント(クラス)を決定する手法です。また、連続変数だけでなく、カテゴリカル変数も含めて解析することができます。従来の手法によるセグメンテーションと比べ、より煩雑で膨大なデータを機械的に分類することができる手法とも言えます。
潜在クラス分析の特長
-
分析に用いる変数の自由度が高い
選択肢で聴取したSAデータだけでなく、MAやLAなど様々な回答形式のデータを用いることが可能です。さらに、それぞれの変数を混ぜて分析することも可能です。
-
統計的基準で最適なセグメント数が決まる
事前の仮説が曖昧であっても、統計的基準(BICなど)によって最適なセグメント数を推奨してくれます。
-
回答者毎の各セグメントへの所属確率が算出される
回答者の所属セグメントは一つに決まるのではなく、各クラスへの「所属確率」として求められます。「一人十色」を前提とした分析となっています。
活用事例
事例 消費者購買データを活用したセグメンテーション
消費者購買データのうち、清涼飲料の購入有無と属性情報を活用したセグメンテーションを例に、 潜在クラス分析を解説します。1. 解析にかけるデータの準備
清涼飲料に関する購買データ(買った/買わない)と、性別/年代の属性データを準備します。
2. 潜在クラス分析を実行(クラス分け)
解析を実行すると、今回のデータからは9クラスが最適という結果が得られた。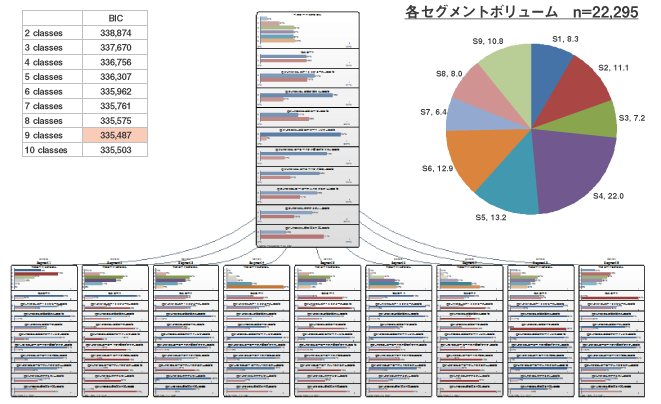
3. 各セグメントの傾向把握とセグメントの決定
今回のケースでは分析の結果、9つのセグメント(Seg1~Seg9)に分類されました。各サンプルの各クラスへの「所属確率」と、最も所属確率が高い「セグメント番号」が紐づきます。例えば、サンプル468は、Seg6に所属する確率は47%、 Seg4は22%、Seg7は15%である‥ということが分かります。個人の多面性をあらわしていると言えます。
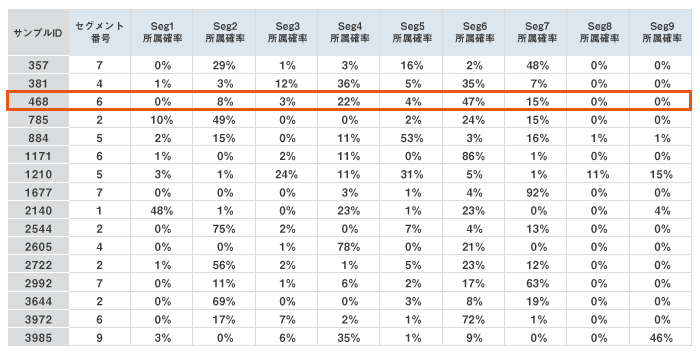
9つのセグメントを集計します。今回は、各サンプルを最も所属確率が高い「セグメント番号」ごとに振り分け、クロス集計やビジュアル化をおこない、回答傾向を確認します。
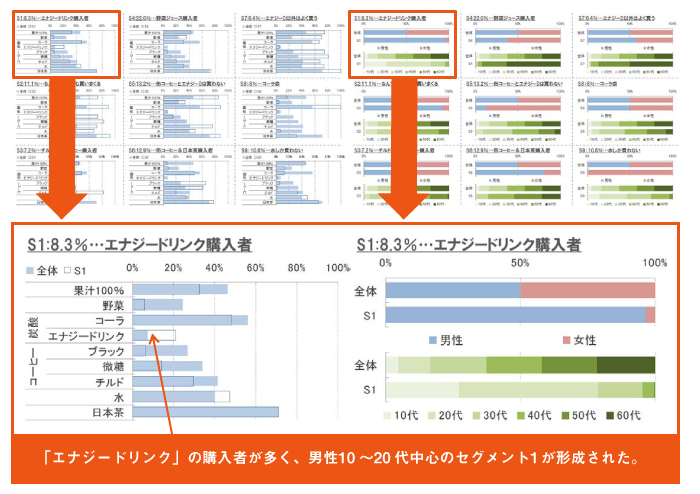
上記のように、購買データや意識データなど異なるデータ形式を組み合わせて、統計的基準をもとに、対象者をセグメント分けすることができます。
潜在クラス分析は、サンプルが必ずどこか特定のクラスターに分類される従来までのクラスター分析と異なり、サンプルが複数のクラスに所属していることを前提とした分析手法です。特定のクラスへの所属確率が高いサンプルに絞ることも可能なため、より特定セグメントへのあてはまり度合いが強いサンプルに対して追加調査/分析をおこなうことも可能です。






