テキストマイニング
大量のテキストデータから、「隠れた」情報や特徴、傾向、互いの関連性を探し出す技術で、自由記述されたデータ(定性情報)をもとに行うデータマイニングです。
※「マイニング」の語源は鉱山から金属の鉱脈を採掘(=Mining)することに由来しており、宝探しという意味です。
テキストマイニングの活用シーン
- 大量のテキストデータをクラスターにまとめて整理し、短い言葉でクラスターの特徴を表現したい。
- 大量のテキストデータの中から、重要語やキーワードを抽出し、その出現頻度や同時出現関係等を分析したい。(全体傾向、重要事項を把握する)
- 大量のテキストデータの中から、キラリと光るアイディアや想定していなかったような斬新な提案、クリティカルなクレームやその兆しを発見したい
- 最近起き始めたこと、問題になり始めたことを見したい
分析事例
事例 単語フラグを立ててクラスター分析を行う
図1の階層クラスターは、10,000人から寄せられたおすすめメニューを分析した結果です。検索系と言われる大量のテキストの分析法としては、『コレスポンデンス分析』や数量化理論3類関連語マップ等があります。今回はおびただしい数の言葉から重要語のみを抜き出し、数量化理論3類を適用した後、その変数スコアから階層クラスターを作成しました(抽出された重要語を数量化3類の変数スコアから、階層クラスター分析をウォード法で実施)。トーナメント表のように見えますが、「似た言葉」=「関連性の高い言葉」を近い順につないでいます。
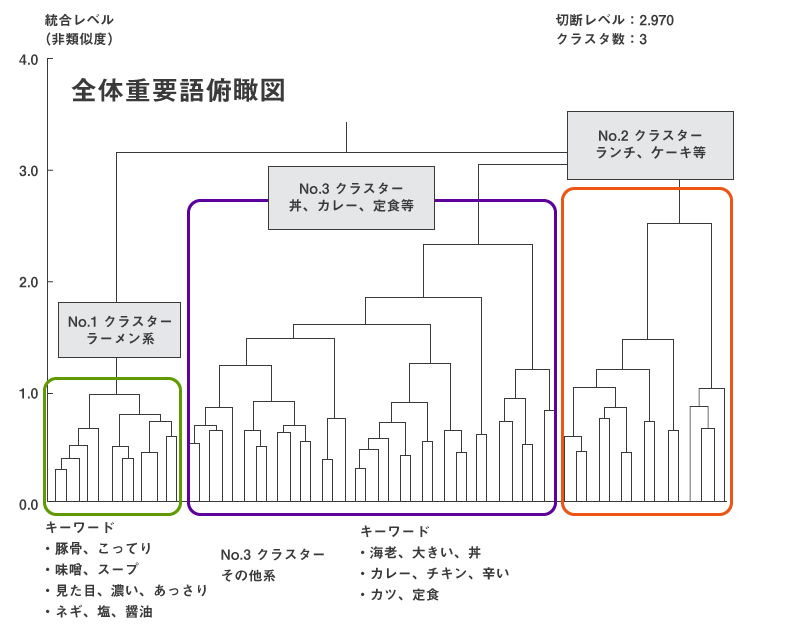
図1
この結果を見ると、調査対象者が美味しいと思うメニューは、大きく3つに分けられることが分かります。一番左がラーメンクラスターで、キーワードとしては、「こってり、豚骨」「スープ、味噌」「見た目、濃い、あっさり」「ネギ、塩、醤油」というものが挙げられました。このことから、人気のメニューは「見た目は濃そうだが意外にあっさりしており、ネギがたっぷりのったネギ塩ラーメンとネギ醤油ラーメン」というイメージでしょう。また2番目のクラスターには、丼系、カレー系、定食系などが見られ、人気があるのは辛いチキンカレー、大きい海老の天丼、トンカツ定食ということになります。
図2は、図1の一番右の「ランチ、ケーキ系」のクラスターを細かく見たものですが、大きく左側のランチコース系とデザート系に分かれます。
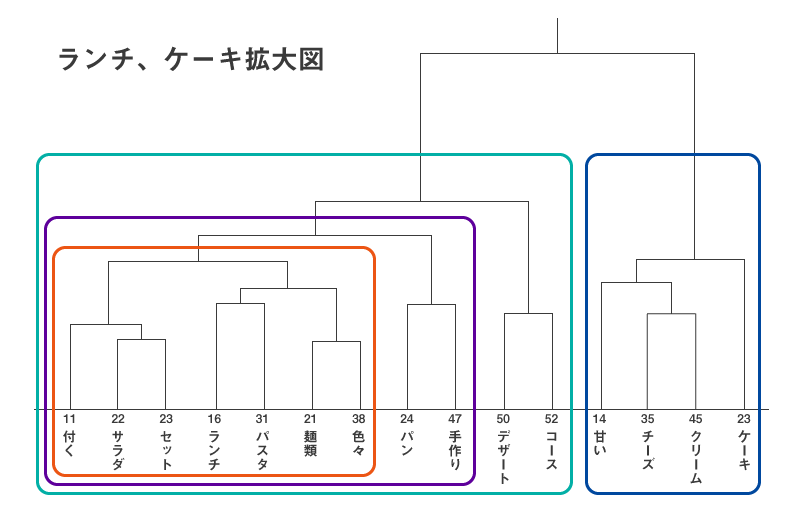
図2
まず、一番関連性が高いのは、この縦線の長さが短い、「サラダ、セット」「麺類、色々」であり、それぞれに「付く」「パスタ、ランチ」が関連している事が分かります。これらの固まりの右に「手作り」「パン」という言葉が出てきており、中程には「パスタ、ランチ」があります。総合すると、人気のランチコースは「色々な種類のパスタが選べ、サラダが付いているセット。パンは手作り」という感じになります。さらに右のクラスターを見ると、「甘いクリームチーズケーキ」も人気のメニューのようです。
このように、テキストマイニングと多変量解析の手法を組み合わせて1万人の自由回答を見ると、日本人のメニューへの意識が手に取るように分かります。さらに男女別、年代別、地域別などで分析したり、時系列での変化などを分析したりすれば、非常に面白い示唆が得られるでしょう。
事例 意味フラグを立てコレスポンデンス分析を行う
図3のマップは、「携帯電話で気に入っている点」について単語や文節それぞれに対していくつかに集約した「意味(かっこいいなど)」を割り振り、そのデータを使ってコレスポンデンス分析を行った結果です。サンプルの特徴は性年齢の区分で表されます。言葉の意味を同時にプロットした同時散布図となり、言葉の分析は単語の頻度だけでなく、文節に分けた上での係り受けも考慮に入れています。
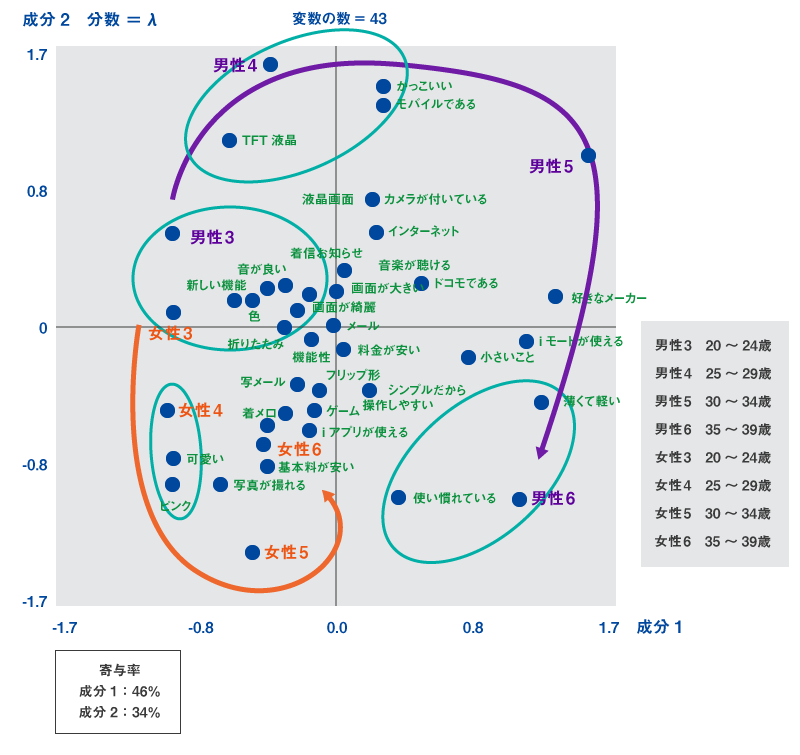
図3
右上が男性方向、左下が女性方向を表しています。男性は液晶が明るいTFT、カメラがついてカッコいい等、女性はピンクでかわいい、写真が撮れる等が気に入っている理由だということが分かります。また、写メール等のことを表現するのに、男性は「カメラがついている」というスペック的見方を、女性は「写真が撮れる」というベネフィット的表現をするところなどが、テキストマイニングならではの結果と言えるでしょう。
このように単語の頻度だけではなく、意味の頻度を分析することで、新しいマーケティング上の示唆を得ることが可能になります。






