
| 連載:マーケティングを成功に導くリサーチ |
|---|
| マーケターがマーケティング・リサーチを正しく活用すれば、マーケティングを成功に導くための貴重な情報が得られます。調査は一見簡単そうに見えますが、そこにはいろいろな落とし穴が潜んでいます。調査のオリエンテーションに始まり調査結果の解釈と意思決定にいたるまで、マーケターは各段階に隠れた落とし穴にはまらないように注意しなければなりません。今回の連載ではマーケティング活動を成功に導くために、マーケティングの活動領域別に調査を活用するヒントを提案していきたいと思います。 |
第3回 生活者を理解する
今回は生活者を理解するためのリサーチについて述べようと思います。ターゲット市場に関して十分な理解があればよいのですが、前例のない市場ではそうもいきません。そういう場合は未開の大地を探検するのにも似た手探りの旅が必要になります。次にマーケット・セグメンテーションのためのガイドを示し、最後に「市場を分ける」ことに何の意味があるかについて私見を述べましょう。
1. 分けることは分かるための第一歩
2020年の東京オリンピックについては費用分担や築地のアクセス道路など、様々な社会問題が起きています。東京招致が決まった当時から東京オリンピックを危惧する意識がなかったわけではありません。
というわけで東京オリンピックという新しいイベントを例にして生活者を理解するための調査について考えてみます。生活者を理解するために、まずは生活者をいくつかのクラスター(集落)に分けてみることにします。
分け方(1) クラスター分析で生活者全体を分割する
分割の標準的な手段としてはクラスター分析がありますので、まずは意識データをそのままクラスター分析にかけてみましょう。 意識変数はX1「仕事が増えるので雇用が改善される」~X20「外国人の観光客はさらに増える」、まで20問を設定しました。7段階評定に対して次のように得点を与えました。
| 「とてもそう思う」 | … | 7点 |
| 「そう思う」 | … | 6点 |
| 「ややそう思う」 | … | 5点 |
| 「どちらともいえない」 | … | 4点 |
| 「あまりそう思わない」 | … | 3点 |
| 「そう思わない」 | … | 2点 |
| 「全くそう思わない」 | … | 1点 |
この調査は学生教育用に2015年に実施したもので、回答者は全国の成人1,000人です。
表1 クラスターの重心とサンプル数
| クラスター番号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| X1 仕事が増えるので雇用が改善される | 4.0 | 5.2 | 1.1 | 2.3 | 1.0 |
| … 途中は省略 … | |||||
| X20 外国人の観光客はさらに増える | 4.6 | 6.0 | 1.6 | 3.8 | 6.0 |
| 各クラスターのサンプル数 | 527 | 373 | 27 | 72 | 1 |
各クラスターがどういう人々なのかを理解するには、①分析変数のデータを使って判断する、②何らかの外部基準とクラスターのクロス集計から解釈する、の2通りの手段しかありません。まず①ですが、20変数の空間内に散らばった1,000人の点を近いもの集めして各クラスターの重心(平均値)を求めたのが表1です。さすがに20変数も評価基準があると情報が咀嚼しきれません。②は分析に使わなかった外部基準を後づけで持ち込んで解釈する方法です。これは外部基準しだいで解釈が変わる危険性があります。
原データをいきなりクラスター分析にかける方法には理論的にも問題がありますので、マーケティングの実務ではほぼ使われません※1。
分け方(2) まず因子分析してから分割する
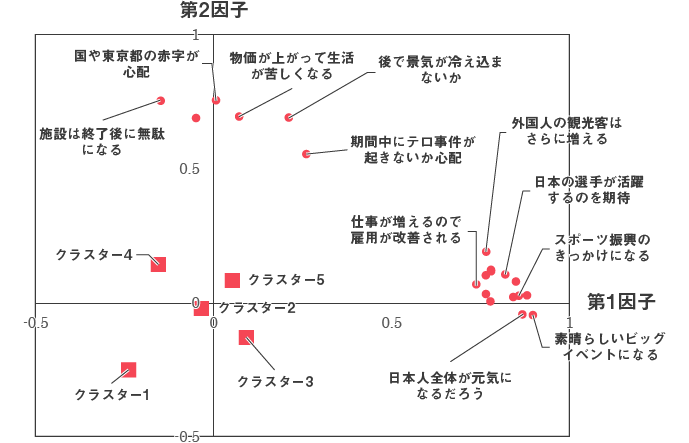
図1 因子分析の結果
(注)クラスターの重心はスケールを変えて図示しています
因子分析を行うと20個の分析変数を図1のような因子空間に位置付けることができます。点の重なった変数名は省略しました。横座標が第1因子で、プラスに大きいほどスポーツの祭典を好意的に評価していることが分かります。これを勝手ながら「歓迎因子」と名付けました。縦座標が第2因子で、これは「心配因子」と名付けました。 ただしこのような因子の解釈には唯一の正解はなく、たんに関係者が了解しやすいようにネーミングしたにすぎません。
因子分析の利点は、元々の20次元の情報を2次元に圧縮しただけではありません。1,000人のサンプルに対して因子得点という2次元のスコアが計算できますので、それをクラスター分析することで、図1の因子空間と関係づけながらクラスターを読み解くことができます。
さて表2がクラスターの解釈です。クラスターとクロス集計する外部基準はいくつあっても構わないのですが、ここでは「東京オリンピックの開催に賛成である」という変数を使って7段階評定の平均値を用いました。
表2 因子分析によるクラスターの解釈
| クラスター番号 | クラスター名称 | 東京オリンピックの 開催に賛成である |
サンプル数 |
|---|---|---|---|
| 3 | 歓迎する意識が強い人々 | 6.1 | 240 |
| 5 | 心配よりも歓迎が勝っている人々 | 5.0 | 251 |
| 2 | 歓迎も心配もほどほどの人々 | 4.3 | 383 |
| 4 | 心配の意識が強い人々 | 1.8 | 92 |
| 1 | 東京オリンピックに冷めている人々 | 1.6 | 34 |
表1と表2のクラスターは各クラスターに所属するサンプル数が違うことから分かるように別物です。クラスター分析さえ使えば、おなじ分割にたどり着くわけではありません。仮に同じ調査データを使って作られたクラスターが違っていても、それは怒ることではなく、当然のことだと受け止めるべきでしょう。
2. 実務適用へのガイド
探索的な姿勢
今回述べた因子分析は、探索的な因子分析と呼ばれるもので検証的な因子分析※2とは区別される方法です。では探索的な因子分析なら全く仮説は要らないのか?というとそうでもありません。 なぜなら東京オリンピックの調査にしてもX1からX20の変数は、どこからか機械的に出てきたものではなく、調査をする側が何らかの仮説をもって設定したものなのです。前節の調査では東京オリンピックに対してはポジティブな意識とネガティブな意識があるに違いないと想定して調査票を作りました。このような「あいまいな仮説」があって初めて探索的な因子分析が実行できるのです。
ですからマーケターにとって理解しやすいクラスターが出てくるかどうかは、偏に調査票の作成に依存します。生活者を理解するのに最も肝心なこの局面において、統計学はほぼ貢献できません。 探索的な因子分析といいながらも実際には「あいまいな仮説」が必要なことを理解してください。仮説が何もないので質問項目も思い浮かばない、ということであればデプス・インタビューやグループインタビュー、その他Listening系の調査を活用して質問項目自体を探索する必要があるでしょう。
計算は大変なのか
昨今は計算環境が良くなっていますので、ユーザーが自ら計算する必要はなくなりました。たいていの統計ソフトが前節の計算をしてくれます。では自動販売機で飲料を買う時のように、「因子分析とクラスター分析」というボタンを押せば、アウトプットが出てくるのかというとそうはいきません。
この2つの分析には、それぞれ多数の解法とオプションがあって、ボタン一つでは済まないからです。ですからこの分析の初心者の方は、専門家に分析を代わってもらうか、習熟するまではアドバイスしてもらうことを強くお勧めします。
多くのオプションにはそれぞれ根拠がありますので、ユーザーはそれぞれの意味を正しく理解して選択しなければなりません※3。
3. 分けることの意味
生活者を分けたその先
マーケティングを成功に導くには、生活者をセグメンテーションしたその先のビジネス展開が大事であると私は考えます。 分割数をいくつにするかは、しょせんは統計学で決められる問題ではなくビジネス側の問題です。セグメントを細分化するほど、同一セグメント内の異質性は減りますから、セグメント内分散は0に近づきます。極端にいえばOne to Oneで顧客に対応できるならそうすればよいし、マス・マーケティングが効率がよいビジネスであれば、マネジメント可能なセグメント数に分割すればよいのです。
問題は、市場を分割してビジネス上何の意味があるのか、ということなのです。確かに意識や価値観の似た人々で市場全体をセグメントできれば生活者の理解にはなります。けれども次の段階として、分割したどのセグメントをターゲットにすれば自社のビジネスが成功するかを知りたいと思うはずです。そのためには、セグメントごとの市場反応が予測できる必要があります。
けれども今回述べたセグメンテーションの方法は、市場反応の予測精度を最大化する基準でセグメンテーションしたわけではありません。
そういう意味で、因子分析⇒クラスター分析という伝統的なアプローチに代わる競合アプローチが、近年関心を集めている機械学習です。「予測が当たるように分割する」のが機械学習です。「なぜ買うのか」「なぜ使ってくれるのか」という問いについてはブラックボックスのままでよくて、ともかく当たれるように生活者を分割します。この2つのアプローチの利害得失は、実用経験を蓄積しなければ評価できませんので、まだ結論づけられる段階にはないでしょう。
ただ市場予測はマーケティング課題として重要ですので、いつか改めてお話しようと思います。
今回のまとめ
★多数の調査項目を総合的に分析して、意識や価値観の異なるセグメントに生活者を分割することができる
★その中から自社の顧客として有望なセグメントを選ぶことをターゲティングという
★生活者を理解して終わるのではなく、次はどうやってそのターゲットに働きかければよいかというマーケティング課題に進むべきだ
| 原データのクラスタリングには、分析変数間の相関を無視して点間距離を測っているという誤りがあります。 | |
| 「検証的な因子分析」とは調査をする以前に、どの変数がどの因子から発生するかをきちんと設定して、その仮説の正しさをデータで検証する方法をさします。それに対して探索的な因子分析ではそれほど明確な仮説を設定しないで因子分析を行う方法です。 | |
| たとえば因子得点はアンダーソン・ルービンの方法で推定しますが、その理由はサンプル間の距離を正しく測るためです。統計分析の詳細を解説することは本連載の趣旨ではないので、因子分析とクラスター分析の理論と使用法は朝野熙彦(2012)「マーケティング・リサーチ」講談社などをご覧ください。 |
著者の紹介
朝野 熙彦
千葉大学卒業後、千葉大講師、筑波大特別研究員の兼任を経て専修大・都立大・首都大教授、多摩大および中央大大学院客員教授を歴任。学習院マネジメントスクール顧問。日本行動計量学会理事。専門はマーケティング・サイエンス。
〔主な著書〕
『最新マーケティング・サイエンスの基礎』、『マーケティング・リサーチ』、『入門共分散構造分析の実際』、『入門多変量解析の実際』以上講談社、『アンケート調査入門』東京図書、『ビジネスマンがはじめて学ぶベイズ統計学』朝倉書店など著書多数