







集計の基本(2)
自由記述(FA)の集計
自由記述(FA:Free Answer)とは
アンケート調査における自由記述には、「言葉」で答えてもらうものと「数値」で答えてもらうものがあります。
アンケート調査における「数値」の自由記述にはどういったものがあるでしょうか。例えば、年齢についての質問や、1カ月あたりの食費についての質問等がイメージしやすいでしょう。 こういった質問は、回答を選択肢にしておいて選ばせる方がいいのではないかと考える方もいるかもしれません。確かに選択肢化できるのであれば、そのほうが集計自体はしやすくなります。しかし、事前にどのくらいの範囲で選択肢を設定するのが適切なのか分からない場合や、そもそも数値自体を選択肢に落とし込みにくい質問もあります。また、あえて「数値」で見せたい結果もあるでしょう。
例えば、このような質問をしたい場合は、直接数値を聞く方が望ましいと言えます。選択肢を作成するには、金額の範囲や最大値をどのように設定するのが適切か想定しにくいためです。

また、アンケート調査における「言葉」の自由記述にはどのようなものがあるでしょうか。あらかじめ決まっている選択肢から選ばせるのではなく、回答者が純粋に想起した自由な意見や感想を集めたい時に用います。例えば以下のような質問です。

自由記述(数値)の集計方法
:平均値、中央値、標準偏差、最小値・最大値自由記述で得られたデータはどのように集計したらよいのでしょうか。まずは、より一般的な数値データの集計から見ていきましょう。自由記述で得られた数値データを集計する際には、まずは(1)平均値、(2)中央値、(3)標準偏差、(4)最小値/最大値の4点を確認することが重要です。
平均値
平均値は、回答結果の算術平均(全数値データを足しあげて、データ数で割ったもの)を指します。中央値
中央値とは、回答結果として得られた数値データを大きい(小さい)順に並べて、ちょうど真ん中の位置にくる数値です。標準偏差
標準偏差は、データのばらつきの大きさを表す指標です。標準偏差を出すには、まず、偏差(各データの値と平均値の差)を出します。次に分散(偏差の2乗の値を全て足しあげて、データ数で割ったもの)を算出し、最後に、分散の平方根を出します。この値が標準偏差です。実際に出力する際には、Excel等の表計算ソフトウェアの関数や分析ツールを用いることが多いでしょう。データのばらつきが大きくなるほど、この標準偏差の値は大きくなります。最小値、最大値
最小値、最大値は、全数値データの中で最も小さい値、最も大きい値です。
これらの4つの数値を確認する必要性について解説します。
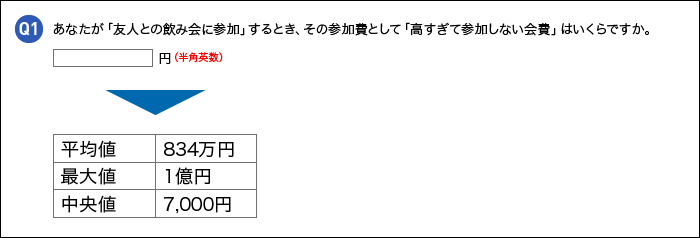
Q1の「高すぎて参加しない会費」を聴いた時、平均値はなんと834万円でした。これは「どんな時でも飲み会に参加したい(と考えている)人」が「1億円」と回答したことによって、平均値がとんでもなく引き上げられてしまった結果です。一方で、中央値は7,000円でした。このように、平均値のみを見ていると、全体の傾向を見誤ってしまう可能性があります。平均値は、極端な最大値や最小値に引っ張られることがあるためです。では、中央値のみを見ればよいのかというとそういう訳でもありません。データのばらつきが大きいときには、中央値も偏った数値を示すことがあります。このように、これら4つの数値を確認することで、全体の傾向を正しく理解することが可能となります。
会社員の平均年収と中央値の違いや、一般家庭の平均貯蓄額と中央値の違いについて等は、メディアにもよく取り上げられています。間違いなく平均値は便利で、誰もが理解しやすい概念ですが、読み解く際には注意が必要です。
自由記述(言葉)の集計方法
:一覧表作成、アフターコーディング、テキストマイニング続いて、数値以外の自由記述をどのように集計していくかを考えます。言葉で集めた調査結果を集計するのに有効な方法として、「アフターコーディング」という処理が知られています。しかし、その前にできることがあります。それは「自由記述の一覧を作成すること」です。
一覧表作成

図1 FAリスト(自由記述の回答一覧表)
先ほどのQ2の質問で、自由記述を多くの人達から聴いた場合、どのような視点で「集めた回答結果(記述)を読んでいきたい」でしょうか。 例えば、「20代と50代ではどんな違いがあるのか」、「男性と女性で記述内容が異なりそう」、「子供の有無で回答に差があるかもしれない」等、様々な視点が考えられます。こういった付加情報(性別、年齢、性別×年齢、職業、居住地、世帯年収・・・等)をつけて自由記述結果の一覧(FAリスト)をまとめることが大切です。
FAリスト作成時に「付加アイテム」として何を選ぶのかによって、出力される記述集の使い勝手は大きく変わってきます。性別や年齢などの属性情報だけではなく、その質問に関連する気持ちを聞いた別の質問の結果等を付加して一覧表を作成するのもいいでしょう。一覧表が作成できたら、Excelのフィルタ機能や並べ変え機能等を上手く活用するとより読みやすくなります。
その他にも、自由記述回答結果を読み込み易くする工夫があります。例えば、FAリストを作成後、
- Excelの関数「LEN」を使い、自由記述回答セル内の文字数をカウントする
- 文字数の多い順に並べ変え/一定の文字数のもののみを絞り込む
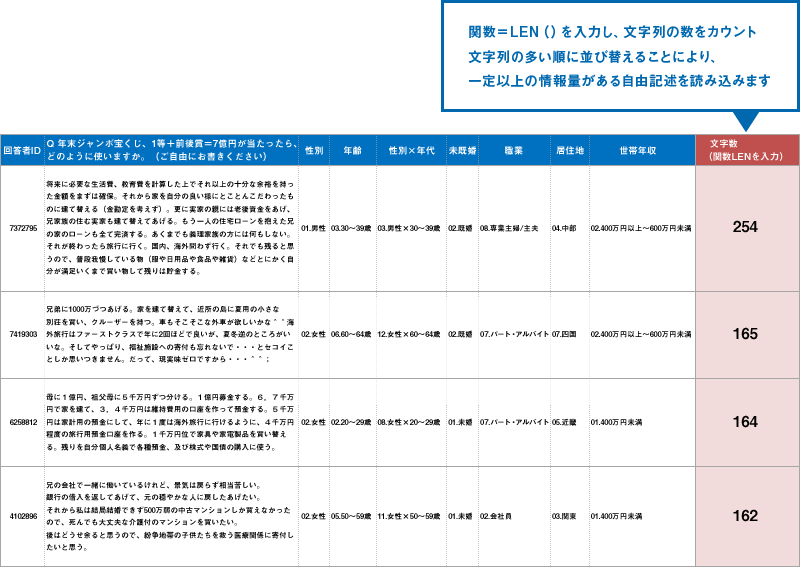
図2
などをしながら、記述文字数の多い回答結果(=情報量が多い)を先に読み込んだり、一定以上の情報量がある回答結果だけを読んだりすることで、読み込みの効率を上げるような工夫も大切です。そのほか、
- キーワードで絞り込む
のも、お勧めです。もちろん、理想は全ての回答を読み込んで、「キラリと光るひとこと」を見逃さないことではありますが、限られた時間の中で調査結果のサマリーを作成しなければならない場合等はこのような工夫も有効です。
アフターコーディング、テキストマイニング
また、自由記述で得られた定性的な情報を定量化したい場合は、「アフターコーディング」という処理が一般的です。「アフターコーディング」とは、自由記述の選択肢化を指します。自由記述の中から類似の回答をまとめ上げて、少数の選択肢に絞り込んでいくことで集計しやすくする手法です。その他にも、昨今では専用のツールを用いた「テキストマイニング」という処理も普及してきました。
「テキストマイニング」とは、文字列を対象としたデータマイニングの事です。自由記述回答結果(文章)を単語や文節で区切り、出現頻度や各単語間の相関などを解析することで、有用な情報を取り出す手法です。どちらにもとても優れた利点がありますが、共通して「定性情報の定量化によって、埋もれてしまう情報がある」という欠点があることを把握しておく必要があります。すなわち「キラリと光るひとこと」を見落とすリスクがあるということです。定性情報の定量化にあたっては、この点を十分に理解し、目的をもって実行することをお勧めします。
- お問い合わせ・集計ソフトのダウンロードはこちら
Myリサーチページログイン