
顧客の多様なニーズを捉えられるクラスターを作ろう
集まるデータを使ったマーケティングの王道が顧客を似た者同士の集団(セグメント)に分割するセグメンテーションである。全顧客を十把一絡げに扱うのではなく、複数の同質集団に分けてマーケティング施策を使い分ける方が効果が大きいのはいうまでもない。年代性別やカードランク別などビジネス側のルールに基づいて行うことも多いが、顧客の様々なデータをもとにクラスター分析を適用することもよく行われる。その際によく使われるのが非階層的なクラスター分析の手法であるk-meansである。k-meansはあらかじめいくつのクラスターに分けたいかを分析者が事前に設定しなければいけない恣意性はあるものの、計算が早く、比較的解釈しやすいクラスターが作れるのでよく利用される。
k-meansでは、ある1人の顧客は必ずどこかのクラスター「1つにだけ」所属するという分け方になる。すべての顧客が漏れなくダブりなくMECEにどれか1つのクラスターに完全に分類される。このような分け方をハードクラスタリングと呼ぶ。
オペレーション上は1人が1つのクラスターに分類されるほうが便利であるが、1人の顧客は必ずしも1つのクラスターの特徴だけを有するわけではなく、複数のクラスターの特徴を併せ持つと考えるほうが自然だ。そこで1人の顧客を、クラスターAに所属する確率は〇〇%、クラスターBに所属する確率は△△%・・・(合計は100%になる)と、それぞれのクラスターに所属する確率で分類していく考え方をソフトクラスタリングという(図1)。
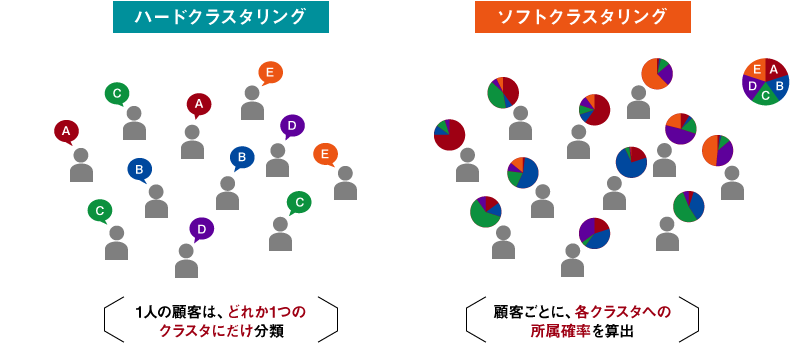
図1 ハードクラスタリングとソフトクラスタリング
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
pLSAを使ってソフトクラスタリングをしてみよう
ソフトクラスタリングをする分析手法として潜在クラス分析などが良く知られているが、ここでは自然言語処理の分野から誕生したトピックモデルの1つであるpLSA(確率的潜在意味解析)という手法をマーケティングのソフトクラスタリングに用いる方法を紹介しよう。
pLSAのしくみについては図2*1の例で説明する。例えば集まるデータであるPOSデータなどから作成した、行方向に顧客ごと、列方向に購入商品を集計し、どの顧客がどの商品を何点購入したかのデータを考える。k-meansなどでは、列方向の商品の購入パターンの類似性を元に行方向の顧客をいくつかの似たもの同士のクラスターに分類するが、pLSAでは列方向の商品も似た買われ方をするという観点で「同時に」クラスターに分類するのが最大の特徴である。このように行側(顧客)と列側(購入商品)を同じクラスターに分けることができるため、特に列側(この場合では購入商品)のクラスターの中味を使ってクラスターの性質を解釈しやすいのも1つの特徴である※2。
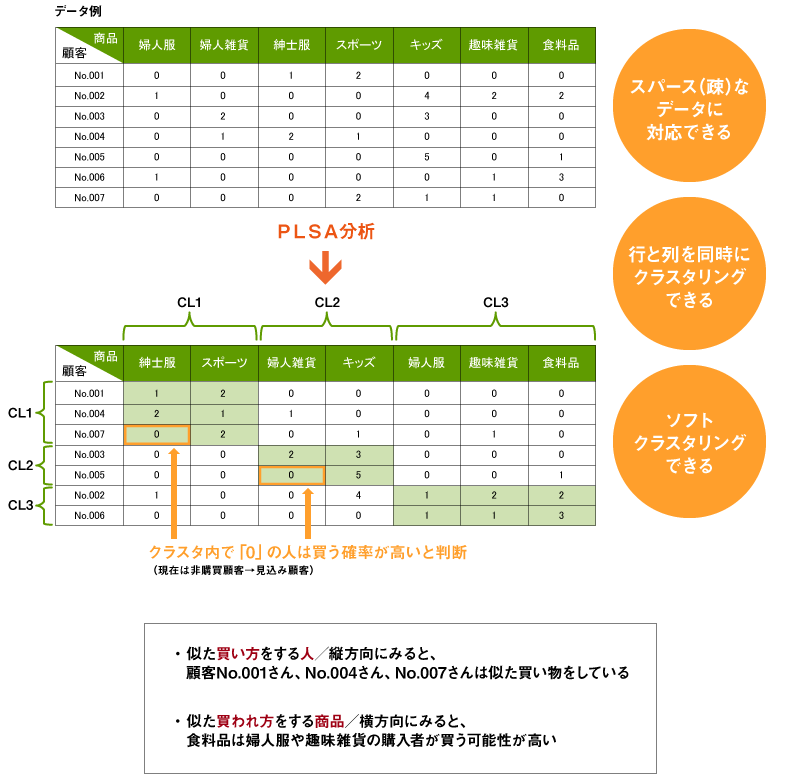
図2 pLSA(確率的潜在意味解析)のしくみ
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
さらにアウトプットとして、図3のように、各顧客がそれぞれのクラスターに所属する確率の一覧が得られる。これがソフトクラスタリングになる。例えば002や006の顧客は圧倒的に1つのクラスターへの所属確率が高いためハードクラスタリングしても問題なさそうであるが、003や011の顧客は複数のクラスターに所属している傾向が見て取れる。013と014の顧客はハードクラスタリングではいずれもクラスター7に分類されることになるが、実際はこの2人のクラスター7への所属度合いはだいぶ異なるものであろう。このように顧客を無理やり最大確率のクラスターに分類してしまうのは、顧客の多様なニーズを捉えているとはいえず、顧客理解の観点からも問題であろう。しかしソフトクラスタリングを行うことで、顧客を実態に合わせより柔軟に分類することが可能になるのだ。
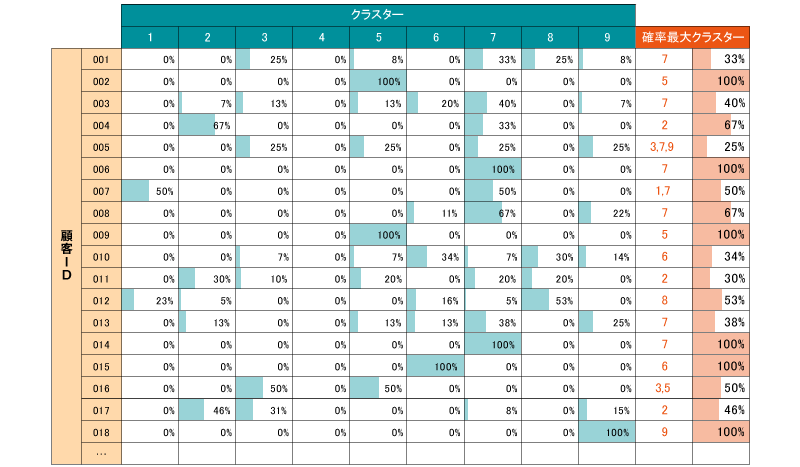
図3 pLSAによって出力される顧客ごとのクラスター所属確率の例
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
その他のメリット
やや技術的ではあるが、pLSAには他にもメリットが多い。最初に書いた通りk-meansではあらかじめ分析者がいくつのクラスターに分割するのかを決めてから分析を行うが、そもそもいくつのクラスターにすべきかは事前にはわからないため、分析者の恣意性が入るし、実務上はいくつものクラスターを作ってみて納得感が得られるクラスター数を決めていくという探索的なアプローチをとる。pLSAでは、各クラスターが合理的に分かれているかを判断する客観的な指標としてAICやBICを利用することが可能であるため※3、その指標を参考に最適なクラスター数を決定できるメリットがある。
またデータがスパースな場合※4、クラスター分析はうまくいかないことが多いが、pLSAは比較的スパースなデータに対しても頑健なため、他の手法ではうまくクラスタリングできない場合でもよいクラスターができる可能性が高い。
今回紹介したpLSAは、何らかの行動・属性データを顧客ごとに集計したデータから顧客をソフトクラスタリングできるという点で、Web閲覧履歴や広告接触履歴、メルマガのクリック履歴など、集まるデータのマーケティング活用への汎用性が高い手法である。マーケターには、硬直的なハードクラスタリングから一歩踏み出せるpLSAをぜひ活用していただきたい。
※1:図2は株式会社東急エージェンシーの資料を基に作成
※2:通常のクラスター分析では、顧客側のみがクラスター化されるため、顧客の属性やそれぞれのクラスターごとの購入商品などを集計してクラスターの性質を類推するが、pLSAでは列側の商品も同時に顧客と同じクラスターに分類するので、そのクラスターにどの商品が含まれているのかを直感的に理解しやすくなる。
※3:AICやBICは複数のモデルの適合度を測る指標で、数値が小さいモデルほど良いモデルと判断する。pLSAでは、例えば5クラスターに分ける場合、6クラスターに分ける場合・・・と複数のクラスター数についてAIC/BICを算出し比較することで最適なクラスター数を決めることができる。ただし最終的なクラスター数は数字のみではなく、マーケターが最も納得感のあるものを採用すべきであるので、AIC/BICはクラスター数のアタリを付ける1つの目安として利用するのが良いだろう。なお、k-meansでもクラスターの結合・分離度合いを数値化した指標が算出できるが、あまり利用はされていないようだ。
※4:スパースについては、第1回コラムを参照
2002年に日本航空株式会社に入社。JALホームページのログ解析や顧客情報分析、航空券などのレコメンド施策の立案・企画・実施を担当。2014年、日経情報ストラテジー誌による「データサイエンティスト・オブ・ザ・イヤー」受賞。2019年より現職、デジタルガレージグループでのデータ活用を統括・推進する。ビジネスアナリティクスや実務に役立つ分析手法に詳しく、データを使ったマーケティングを得意とする。総務省統計局講座や大学での講演・記事掲載など多数。





お客さまの課題・ニーズを伺ってリサーチの企画・提案を行います。
お気軽にお問い合わせください。


