
階層的なデータを分析してみよう
「集まるデータ」の中には、例えば全国都道府県の店舗ごとに売り上げなどが集計されたものや、ID-POSデータのようにある1つの店舗であっても1人の顧客の複数回の購入を記録しているようなデータもある。これらに共通することは、1件1件のレコードは個別店舗や個人のトランザクションであっても都道府県名や顧客番号で括ることができ、階層的な構造をしたデータであることだ。データに現れる変数も、最小単位の個別店舗や個別購買レベルと、都道府県や顧客など集団レベルの2種類があり、集団レベルの変数は同じ都道府県、同じ顧客であればすべて同一の値を取る変数となっている(図1-1、図1-2)。
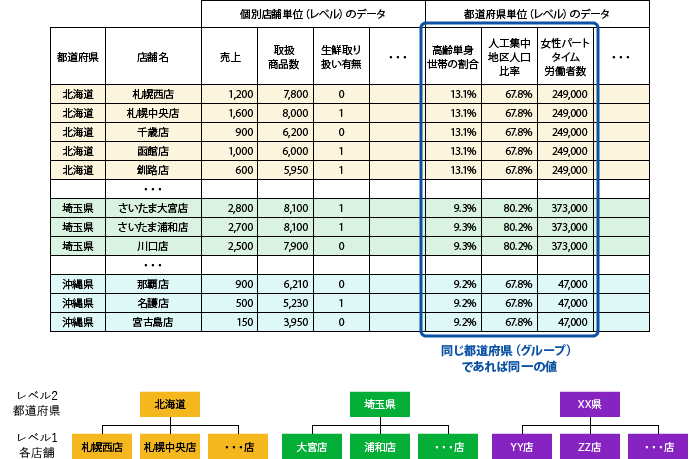
図1-1 階層的な構造を持つデータの例
(都道府県ごとにグループ化された各店舗のデータ)
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
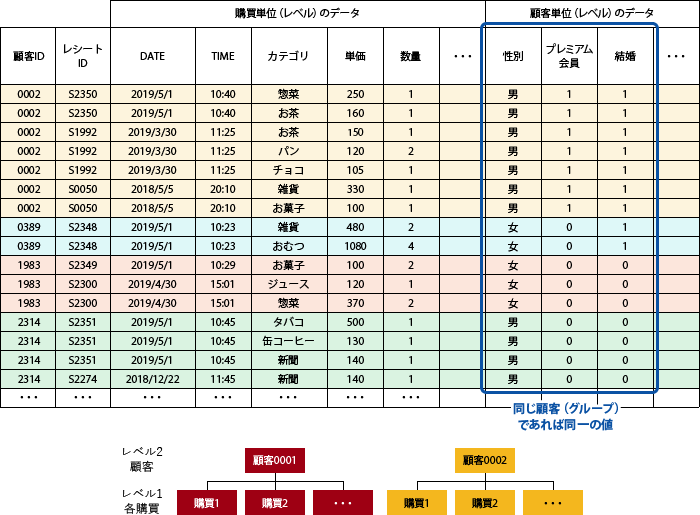
図1-2 階層的な構造を持つデータの例
(個客IDごとにグループ化された各購買のデータ(ID-POSデータ))
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
このような階層的な構造のデータに対し、階層(集団の存在)を考慮せずに回帰分析などを実施するのは次の2つの例を見れば望ましくないことがわかるだろう。図2-1の事例は、散布図を描くと全体としては相関関係があるように見えるが、サブ集団で分けてみると相関が消えてしまうものである。図2-2の事例は逆に、散布図を描くと全体で相関は見られないが、サブ集団に分けてみるとそれぞれの集団内では相関関係が見られるケースである。いずれの場合も集団の存在を無視し、データ全体に対し1つの回帰式だけで説明しようとすると無理が生じる*1。
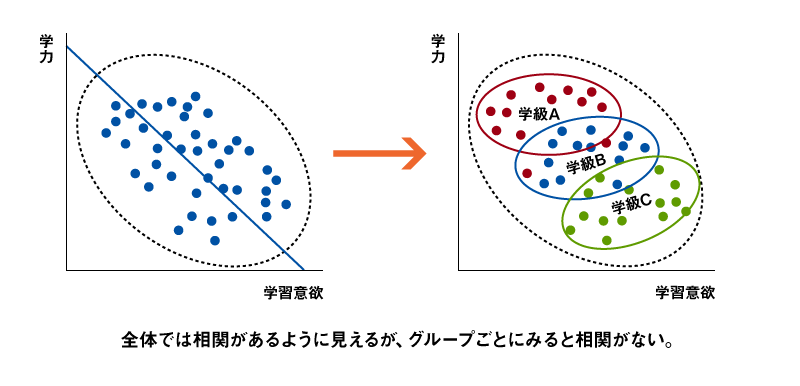
図2-1 階層的な構造を持つデータのグループごとの無相関
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
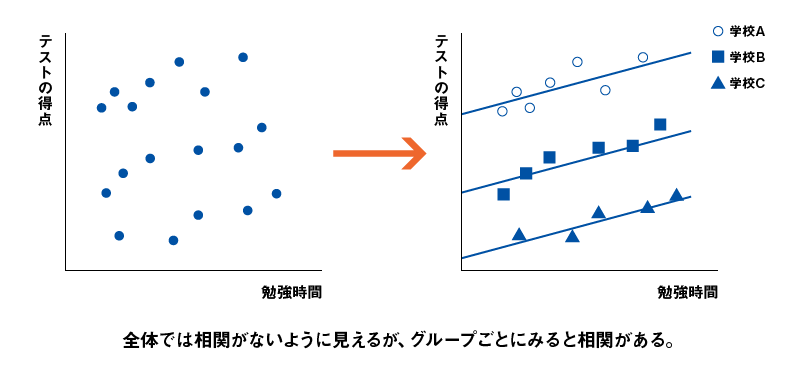
図2-2 階層的な構造を持つデータのグループごとの相関
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
マルチレベル分析で解決
このような階層データに回帰分析を適用する際、最初に思い浮かぶのは集団ごとにデータを分割して回帰分析をする方法である。しかし集団に分割すると1つの集団に含まれるサンプルサイズが小さくなりパラメータの推計が不安定になってしまう他、例えば都道府県の場合47回も回帰分析を実施し、47個それぞれの傾きや切片などのパラメータを個別に読み取るのは手間がかかるし困難である。
そこでこのような階層的なデータを分析する手法としてマルチレベル分析がある*2。マルチレベル分析では、通常の回帰分析のように傾きと切片を求めるが、その際、傾きや切片を定数ではなく、定数+正規分布に従う「ばらつき」として表現する。こうすることで、例えば47都道府県の場合であれば、47個の傾きや切片を個別に求めるのではなく、統一した構造(ある定数+ばらつき)として捉えることができるようになる。傾きは定数のみ(固定)にして、切片のみにばらつきを考慮する「ランダム切片モデル」、切片は定数のみ(固定)として傾きのみにばらつきを考慮する「ランダム傾きモデル」、切片と傾き両方にばらつきを考慮する「ランダム切片・傾きモデル」など、データの当てはまりに応じて柔軟にモデルを選択すればよい。直感的には、47都道府県の違いも反映しつつ、全体としての構造を統一的に説明するモデル、と言えるだろう。
駅ごとの不動産価格の予測にマルチレベル分析を適用した事例
マルチレベル分析をマーケティングデータに適用した事例はあまり多くないが、賃貸物件の価格を駅ごとに予測する面白い分析事例があるので紹介したい(図3)※3。
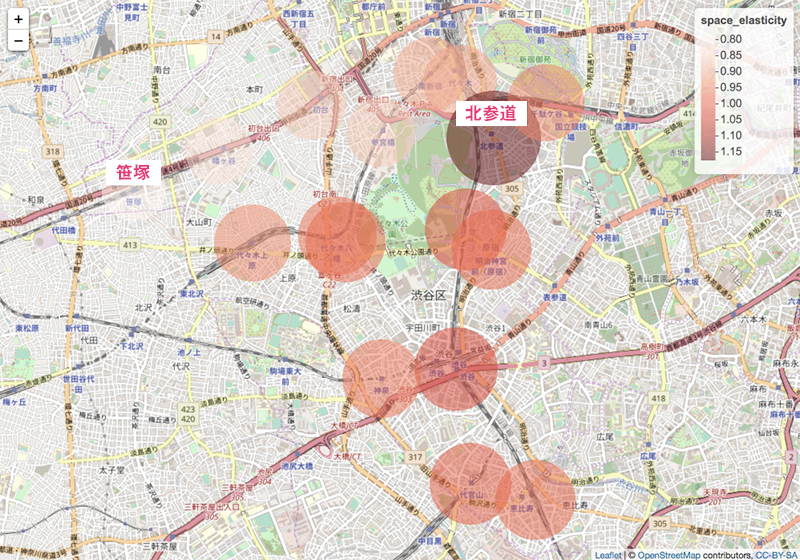
図3 渋谷区の駅ごとに家賃の弾力性
To return to the previous page, click on the part of the window where the image is not displayed, or press the close button.
この事例では、渋谷区内の17駅付近に分布する4,725件の賃貸物件の価格と専有面積のデータに対し、マルチレベル分析を適用して、「鉄道駅ごとの違いも考慮しつつ、渋谷区全体での家賃の傾向を把握する」ことを試みている※4。
分析の結果、駅ごとに家賃のベースが異なっていること(ランダム切片)と、駅ごとに専有面積に対する家賃の上昇率が異なる(ランダム傾き)ことを発見している。駅ごとに回帰モデルをバラバラに作るよりも、渋谷区全体としての1つのモデルを作り、全体傾向からのずれの度合いを駅ごとに同一の次元で比べられる点が優れている。この事例では、傾きを家賃の価格弾力性に読み替え、それが対照的な北参道駅と笹塚駅を取り上げ、住むなら笹塚駅周辺の物件のコスパがいいことを見出している。
このように、マーケティングの「集まるデータ」には階層的な構造をしているデータが多く、集団(グループ)ごとに分析をしてその差異から得られる洞察を求めたいマーケターは多いだろう。マルチレベル分析は線形回帰にちょっと工夫を凝らした応用テクニックであり決して難解ではないので、ぜひ活用してもらいたい。
※1:規模の大きい全国的なアンケート調査でよく行われる層化二段抽出法などは典型的な階層データの構造を持つが、実際の分析は階層構造を無視して行われていることが多い。
※2:階層線形モデル、線形混合モデルなどと呼ばれることもある。パラメータの分布を正規分布に限らず、より柔軟な構造を表現する階層ベイズモデルなども最近は使われるようになったが、本稿ではもっとも簡単な線形モデルに限って説明する。なお、理論的には何階層でも分析可能であるが、3階層以上の分析は解釈も煩雑になるため、ほとんどの場合2階層までとするのが現実的である。
※3:R|階層線形モデルで渋谷区の賃貸価格を予想する( hanaoriさん noteより引用)
※4:ただしこの事例では駅レベルの変数として、例えば乗降客数などのデータは利用していない。
2002年に日本航空株式会社に入社。JALホームページのログ解析や顧客情報分析、航空券などのレコメンド施策の立案・企画・実施を担当。2014年、日経情報ストラテジー誌による「データサイエンティスト・オブ・ザ・イヤー」受賞。2019年より現職、デジタルガレージグループでのデータ活用を統括・推進する。ビジネスアナリティクスや実務に役立つ分析手法に詳しく、データを使ったマーケティングを得意とする。総務省統計局講座や大学での講演・記事掲載など多数。





お客さまの課題・ニーズを伺ってリサーチの企画・提案を行います。
お気軽にお問い合わせください。


